dian lv(a和b方案存在显著性差异,)
A/Btest
- 分组必须遵循随机的原则
如我们在左边区域的门店实施A方案,而在右边区域的门店实施B方案,这样就违背的随机分组原则,实际会受到地域因素的影响。
- 假设检验
是否存在显著性差异?如果A/B无差异,可能是偶然误差。
在大数据下,因数据量大小导致的偏差已经很小,在具有统计学意义的情况下,还需要探讨差异在现实模式中是否有意义。
背景
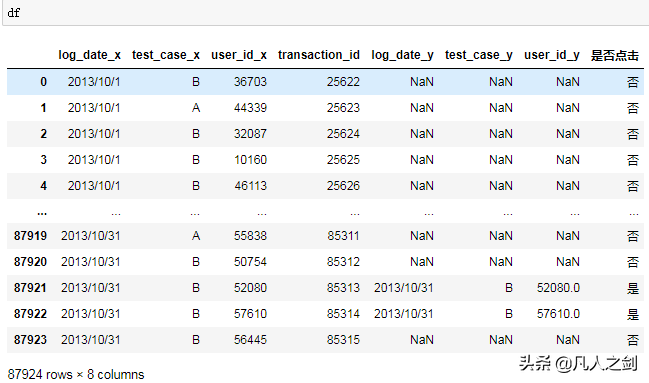
如有两个广告投放方案需要对比效果,已经随机分组进行一段时间的实施,有如下日志,其中transaction_id为曝光时生成的ID,作为KEY:
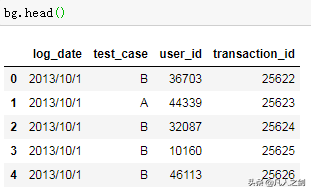
- 曝光日志
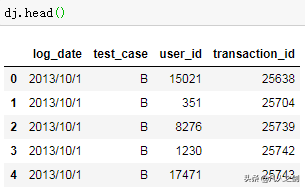
- 点击日志
数据合并
- 广告事件流程:曝光→点击
- 数据量大小:曝光>点击
- 合并方式:左连接
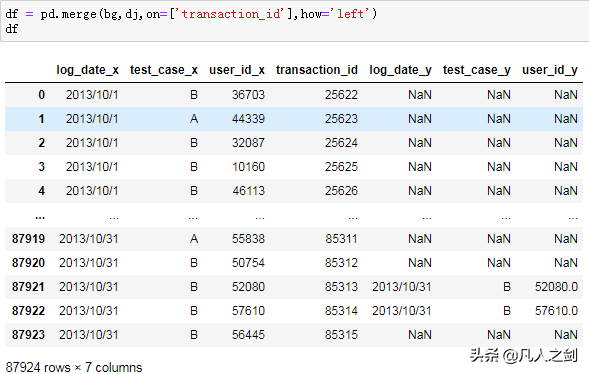
有空值的为没有点击
数据处理
- 创建标志位
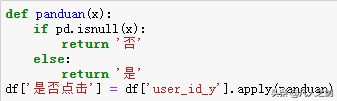
数据准备
- 只选取所需列

- 建立交叉表

- 点击率
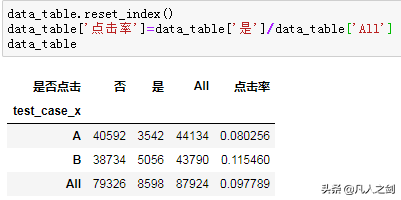
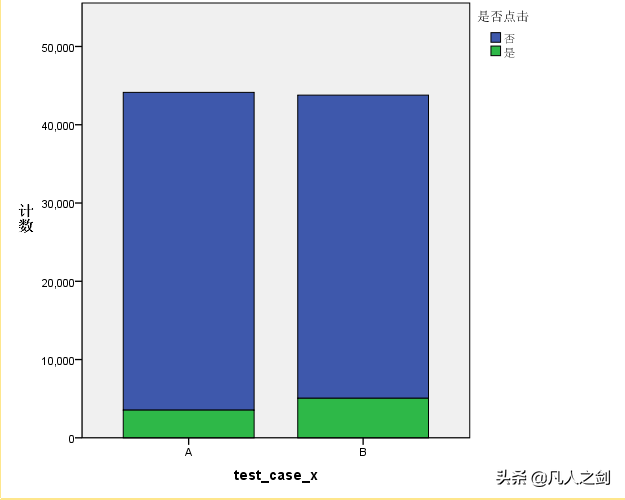
可以看到,A/B实施数量基本无差异,且方案B的点击率要高于方案A。
假设检验之卡方检验
- 前提: 自变量和因变量均为定类数据,自变量组别为两组或以上,样本量有要求,样本量小的要用Fisher检验。
- 检验数据选取
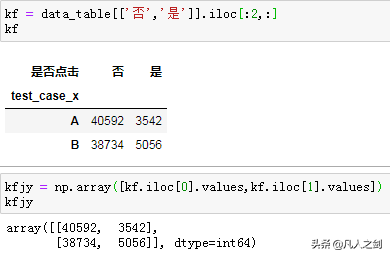
- 检验数据
from scipy import stats
out = stats.chi2_contingency(kfjy)[0:3]
out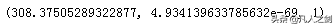
得出3个数,分别为卡方值,P值,自由度。
其中自由度为1,公式为:交叉表中(行数-1)*(列数-1)
定义的检验假设(无效假设)H0:A和B方案无差异
备择假设H1:A和B方案存在显著性差异
在这里P值远小于0.05,是小概率事件,拒绝原假设,即A和B方案存在显著性差异。
现实意义
查看每日点击率变化
- 选取所需列
- 转换时间类型,不然不能自动排序
- 将是否替换为0,1,需要计算点击率
- 增加一列辅助列,用于统计总数
d1 = df[['log_date_x','test_case_x','是否点击']]
d1['log_date_x']=d1['log_date_x'].astype('datetime64')
d1.replace(to_replace='否',value=0,inplace=True)
d1.replace(to_replace='是',value=1,inplace=True)
d1['辅助列']=d1['是否点击']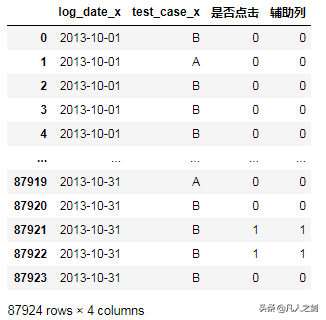
- 分类汇总,分别对两列进行sum和count,算出点击数和总数,用于计算点击率
dianjilv = d1.groupby(['test_case_x','log_date_x']).agg({'是否点击':'sum','辅助列':'count'}).reset_index()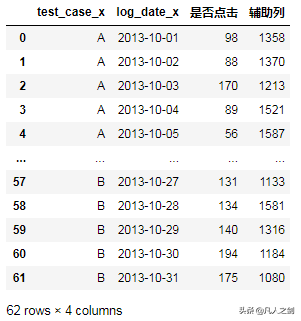
- 计算点击率
dianjilv['点击率']=dianjilv['是否点击']/dianjilv['辅助列']
dianjilv.to_csv(r'...\点击率.csv',index=False,encoding='utf_8_sig')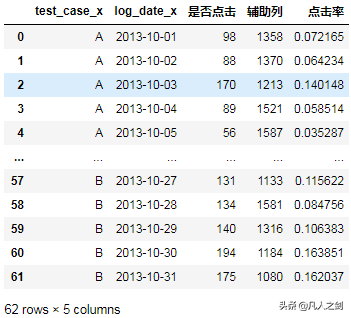
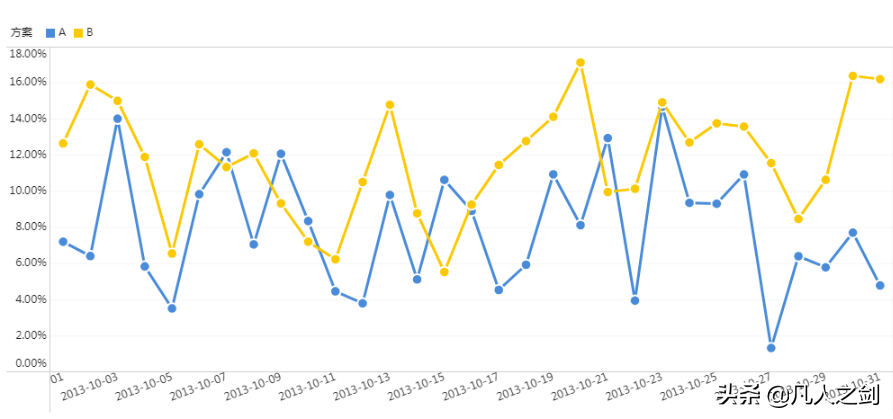
可以看到,B方案总体都由于A方案。
SPSS
SPSS也是通过交叉表

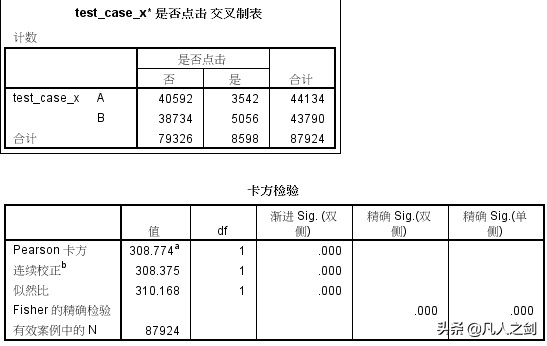
其中df为自由度
渐进Sig为0远小于0.05,也是拒绝原假设。
本文经用户投稿或网站收集转载,如有侵权请联系本站。